Para variables numéricas, en las que puede haber un gran número de valores observados distintos, se ha de optar por un método de análisis distinto, respondiendo a las siguientes preguntas:
- ¿Alrededor de qué valor se agrupan los datos?
- Supuesto que se agrupan alrededor de un número, ¿cómo lo hacen? ¿muy concentrados? ¿muy dispersos?
Las medidas de centralización vienen a responder a la primera pregunta. La medida más evidente que podemos calcular para describir un conjunto de observaciones numéricas es su valor medio. La media no es más que la suma de todos los valores de una variable dividida entre el número total de datos de los que se dispone.
Como ejemplo, consideremos 10 pacientes de edades 21 años, 32, 15, 59, 60, 61, 64, 60, 71, y 80. La media de edad de estos sujetos será de:
Más formalmente, si denotamos por (X1, X2,...,Xn) los n datos que tenemos recogidos de la variable en cuestión, el valor medio vendrá dado por:
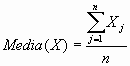
Otra medida de tendencia central que se utiliza habitualmente es la mediana. Es la observación equidistante de los extremos.
La mediana del ejemplo anterior sería el valor que deja a la mitad de los datos por encima de dicho valor y a la otra mitad por debajo. Si ordenamos los datos de mayor a menor observamos la secuencia:
15, 21, 32, 59, 60, 60,61, 64, 71, 80.
Como quiera que en este ejemplo el número de observaciones es par (10 individuos), los dos valores que se encuentran en el medio son 60 y 60. Si realizamos el cálculo de la media de estos dos valores nos dará a su vez 60, que es el valor de la mediana.
Si la media y la mediana son iguales, la distribución de la variable es simétrica. La media es muy sensible a la variación de las puntuaciones. Sin embargo, la mediana es menos sensible a dichos cambios.
Por último, otra medida de tendencia central, no tan usual como las anteriores, es la moda, siendo éste el valor de la variable que presenta una mayor frecuencia.
En el ejemplo anterior el valor que más se repite es 60, que es la moda
b. Medidas de dispersión
Tal y como se adelantaba antes, otro aspecto a tener en cuenta al describir datos continuos es la dispersión de los mismos. Existen distintas formas de cuantificar esa variabilidad. De todas ellas, la varianza (S2) de los datos es la más utilizada. Es la media de los cuadrados de las diferencias entre cada valor de la variable y la media aritmética de la distribución.
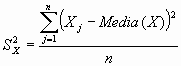
Esta varianza muestral se obtiene como la suma de las de las diferencias de cuadrados y por tanto tiene como unidades de medida el cuadrado de las unidades de medida en que se mide la variable estudiada.
En el ejemplo anterior la varianza sería:
La desviación típica (S) es la raíz cuadrada de la varianza. Expresa la dispersión de la distribución y se expresa en las mismas unidades de medida de la variable. La desviación típica es la medida de dispersión más utilizada en estadística.
Sx2=
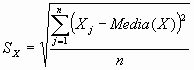
Aunque esta fórmula de la desviación típica muestral es correcta, en la práctica, la estadística nos interesa para realizar inferencias poblacionales, por lo que en el denominador se utiliza, en lugar de n, el valor n-1.
Por tanto, la medida que se utiliza es la cuasidesviación típica, dada por:
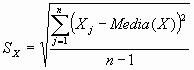
Aunque en muchos contextos se utiliza el término de desviación típica para referirse a ambas expresiones.
En los cálculos del ejercicio previo, la desviación típica muestral, que tiene como denominador n, el valor sería 20.678. A efectos de cálculo lo haremos como n-1 y el resultado seria 21,79.
El haber cambiado el denominador de n por n-1 está en relación al hecho de que esta segunda fórmula es una estimación más precisa de la desviación estándar verdadera de la población y posee las propiedades que necesitamos para realizar inferencias a la población.
Cuando se quieren señalar valores extremos en una distribución de datos, se suele utilizar la amplitud como medida de dispersión. La amplitud es la diferencia entre el valor mayor y el menor de la distribución.
Por ejemplo, utilizando los datos del ejemplo previo tendremos 80-15 =65.
Como medidas de variabilidad más importantes, conviene destacar algunas características de la varianza y desviación típica:
Otra medida que se suele utilizar es el coeficiente de variación (CV). Es una medida de dispersión relativa de los datos y se calcula dividiendo la desviación típica muestral por la media y multiplicando el cociente por 100. Su utilidad estriba en que nos permite comparar la dispersión o variabilidad de dos o más grupos. Así, por ejemplo, si tenemos el peso de 5 pacientes (70, 60, 56, 83 y 79 Kg) cuya media es de 69,6 kg. y su desviación típica (s) = 10,44 y la TAS de los mismos (150, 170, 135, 180 y 195 mmHg) cuya media es de 166 mmHg y su desviación típica de 21,3. La pregunta sería: ¿qué distribución es más dispersa, el peso o la tensión arterial? Si comparamos las desviaciones típicas observamos que la desviación típica de la tensión arterial es mucho mayor; sin embargo, no podemos comparar dos variables que tienen escalas de medidas diferentes, por lo que calculamos los coeficientes de variación:
CV de la variable peso =
CV de la variable TAS =
A la vista de los resultados, observamos que la variable peso tiene mayor dispersión.
Cuando los datos se distribuyen de forma simétrica (y ya hemos dicho que esto ocurre cuando los valores de su media y mediana están próximos), se usan para describir esa variable su media y desviación típica. En el caso de distribuciones asimétricas, la mediana y la amplitud son medidas más adecuadas. En este caso, se suelen utilizar además los cuartiles y percentiles.
Los cuartiles y percentiles no son medidas de tendencia central sino medidas de posición. El percentil es el valor de la variable que indica el porcentaje de una distribución que es igual o menor a esa cifra.
Así, por ejemplo, el percentil 80 es el valor de la variable que es igual o deja por debajo de sí al 80% del total de las puntuaciones. Los cuartiles son los valores de la variable que dejan por debajo de sí el 25%, 50% y el 75% del total de las puntuaciones y así tenemos por tanto el primer cuartil (Q1), el segundo (Q2) y el tercer cuartil (Q3).

0 comentarios:
Publicar un comentario